前言
在 AI 算力成为迷你主机核心竞争力的当下,华硕 NUC 系列始终以前沿硬件技术与全能场景适配,为行业树立标杆。此次推出的华硕 NUC16 Pro,正是面向本地 AI 应用打造的性能旗舰。它搭载英特尔全新 Panther Lake 架构的 Intel Core Ultra X7 358H 处理器,采用突破性的 Intel 18A 制程工艺打造,配合内置的 Intel Arc B390 核显(12 个 Xe3 核心)与 NPU 5 AI 加速引擎,平台总 AI 算力高达 180 TOPS,堪称目前迷你主机市场中 AI 算力最为强悍的产品之一。
本篇测评,我们将聚焦其核心亮点AI性能,开展全维度深度专项测试:从NPU算力基准跑分、本地AI推理效率实测,到 OpenClaw本地部署的完整流程演示与实战效果验证,全方位拆解其在本地AI场景下的实用性。
Ai性能测试
Al Text Generation Benchmark,该基准测试可以测试和比较设备执行本地大型语言模型推理任务的性能,例如使用设备上的AI助手来协助完成简单的办公任务。它可运行多达四个工作负载,且设计适用于集成和独立显卡。
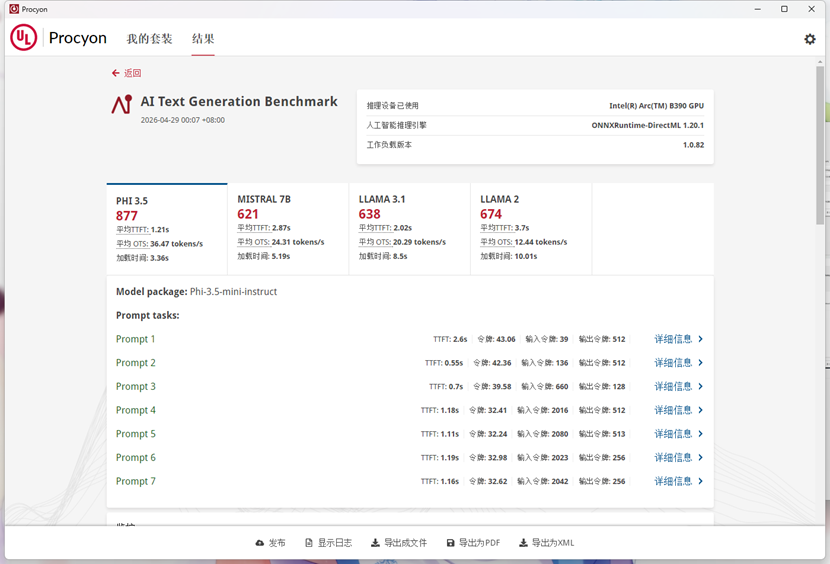
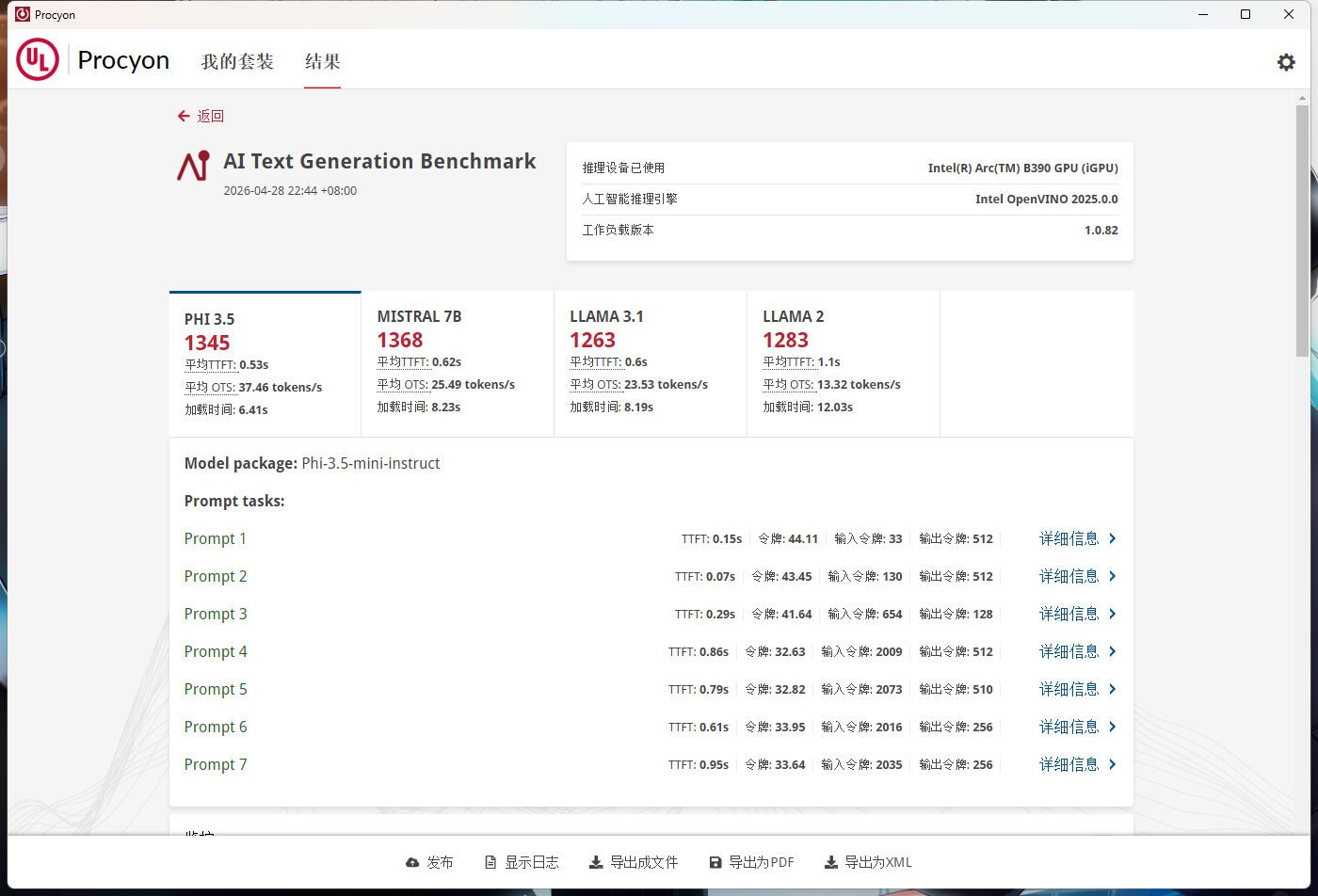
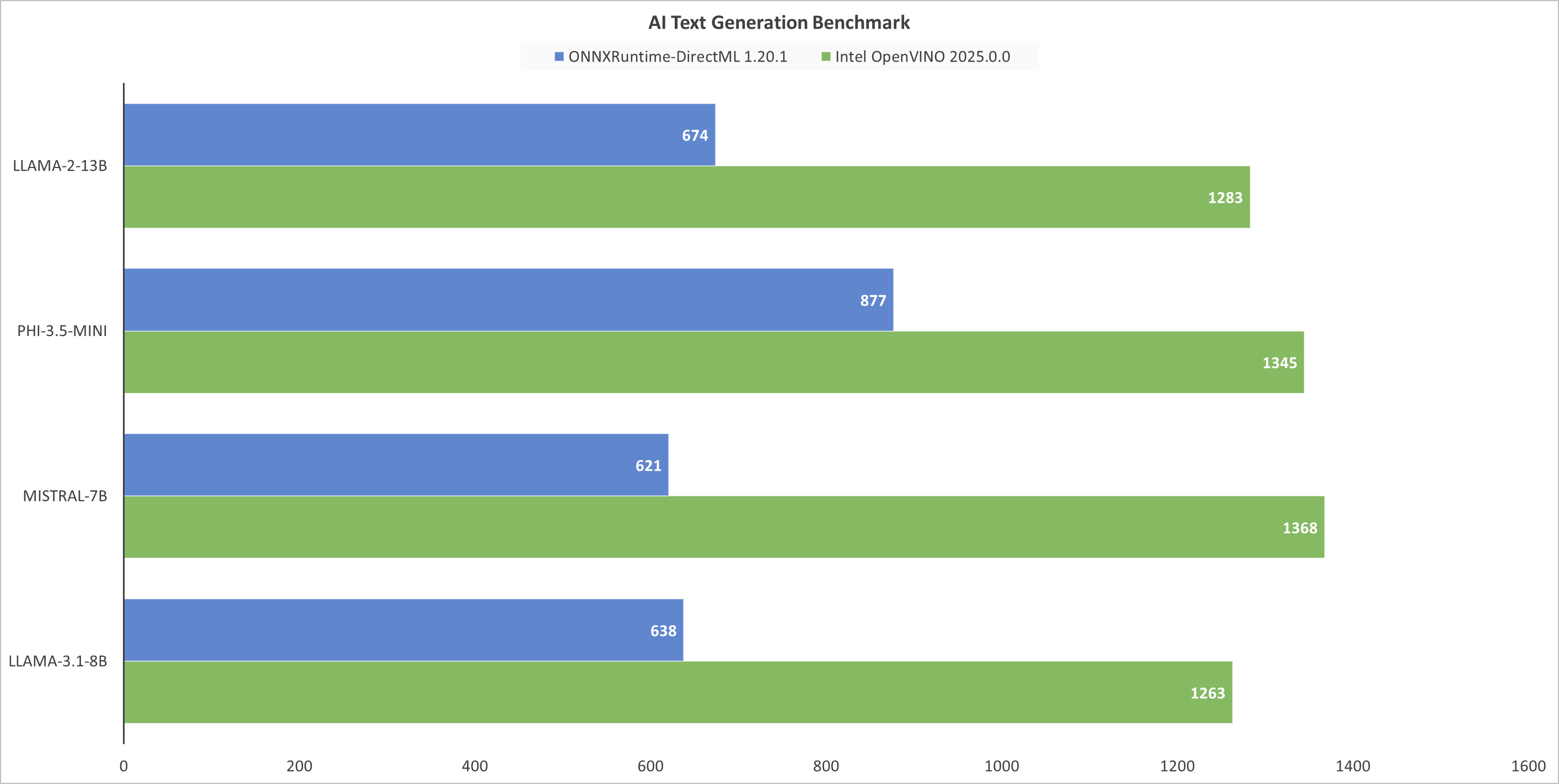
1. OpenVINO 优化效果显著
OpenVINO 作为英特尔原生 AI 推理框架,针对处理器的 NPU 和 Arc B390 核显做了深度适配优化,尤其是对 7B/8B/13B 级别的大模型,性能提升普遍达到 90% 以上,MISTRAL-7B 甚至实现了翻倍增长。
2. PHI-3.5-MINI 模型表现突出
这是测试中 OpenVINO 下得分最高的模型,平均生成速度达到 37.46 tokens/s,TTFT(首 token 生成时间)仅 0.53s,几乎实现了 “零延迟响应”,在轻量级对话场景中体验极佳。
3. 大模型也能流畅运行
即便是 13B 参数的 LLAMA-2 模型,在 OpenVINO 优化下也能达到 13.32 tokens/s 的生成速度,TTFT 仅 1.11s,完全可以满足日常本地 AI 对话、文案生成等需求,无需依赖云端算力。
Intel Core Ultra X7 358H 是一枚具备较高AI推理效率的处理器,尤其配合 Intel OpenVINO 引擎时,可流畅运行7B-8B参数模型(如 Llama-3.1、Mistral),并能在低延迟下完成轻量级对话任务。相比 Arrow Lake 的 Intel Core Ultra 7 265H,GPU AI 文本生成性能提升显著。如果使用场景是离线文本生成、代码补全或本地知识问答,该处理器完全能够胜任,无需额外独立显卡。
-
轻量级对话/问答:PHI-3.5-MINI 模型的表现可以媲美部分云端对话助手,生成速度快、延迟低,适合日常聊天、信息查询等场景。
-
创意文案/代码生成:MISTRAL-7B、LLAMA-3.1-8B 模型在 OpenVINO 优化下,生成速度稳定在 25 tokens/s 以上,能高效完成文案撰写、代码片段生成等任务。
-
本地隐私AI应用:得益于本地运行的特性,所有数据都无需上传云端,搭配处理器的高 AI 性能,适合处理敏感信息的 AI 任务,兼顾效率与隐私安全。
Al Computer Vision Benchmark使用常见的API和推理机,对Windows设备中的CPU、GPU和AI加速器的AI推理性能进行基准测试和比较。使用此测试可以比较哪种API和硬件配置可以在执行常见机器视觉任务时,为您的Windows设备提供最好的AI性能。
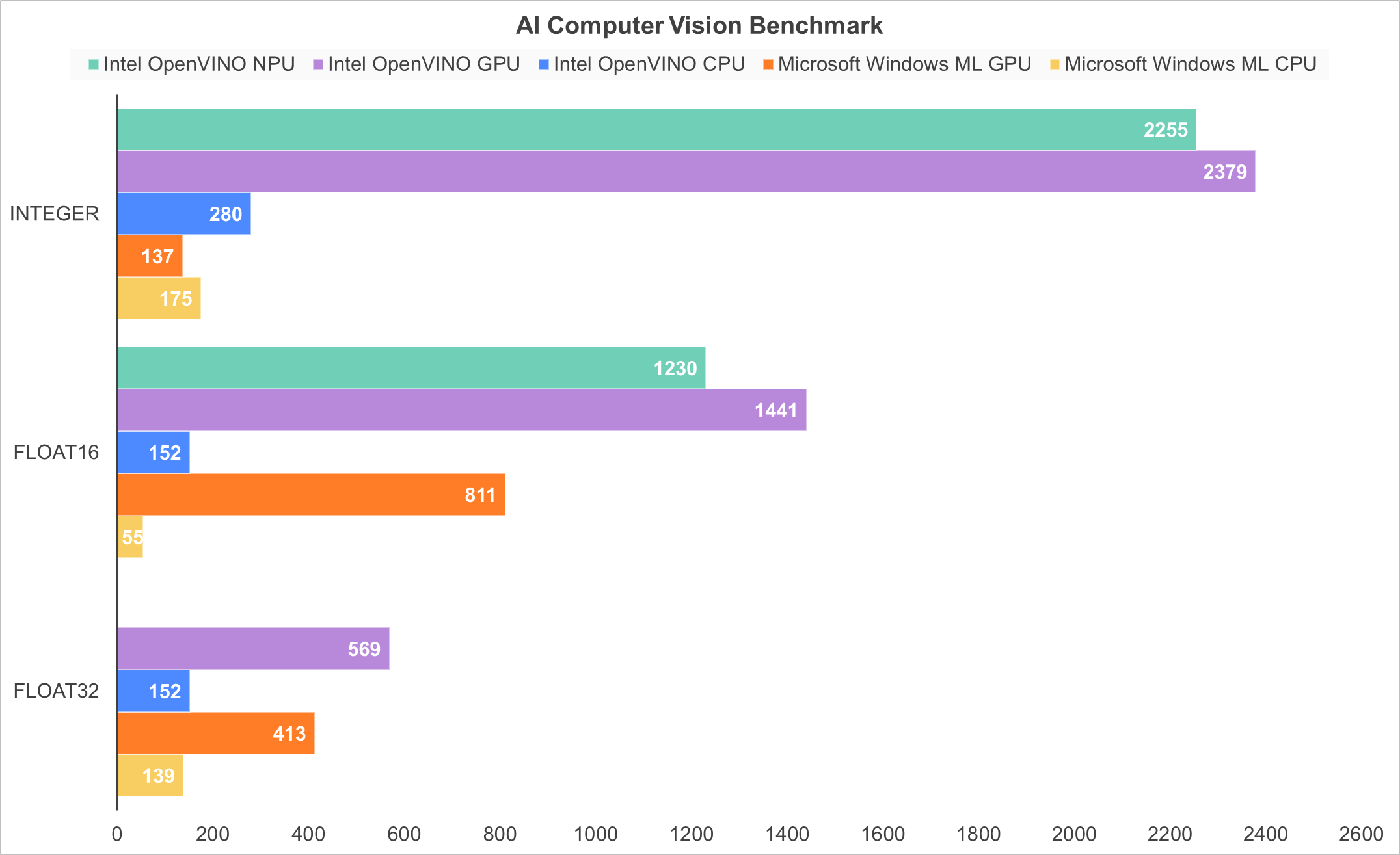
-
Arc B390 核显(Intel OpenVINO) 在所有精度下都是性能天花板,尤其是整数运算,得分高达 2379,远超其他方案。
-
内置 NPU(Intel OpenVINO) 紧随其后,在整数和 FP16 精度下展现了极强的专用加速能力。
-
CPU 与 Microsoft Windows ML 框架的表现则相对普通,差距非常明显。
Arc B390 GPU 和 NPU 的性能几乎是 CPU 的 8 倍以上,整数运算(图像分类、目标检测等视觉任务的主流精度)被彻底优化,是该处理器的绝对优势项。FP16 是 AI 推理最常用的精度,这里 GPU 和 NPU 依然碾压式领先,同时 Windows ML GPU 的表现也不错,但仍落后 OpenVINO 优化的 Arc 核显约 45%。FP32 不是 AI 推理的主流精度,更多是传统计算场景,此时核显的优势依然存在,但差距有所缩小。
Intel Core Ultra X7 358H处理器的 Arc B390 核显和NPU都为AI视觉任务做了硬件级优化,但必须搭配 Intel OpenVINO 这样的原生框架才能释放全部性能。使用通用的 Windows ML 框架,即便是同一块硬件,性能也会大幅缩水。
Geekbench AI 是一款跨平台 AI 基准测试工具,它使用真实世界的机器学习任务来评估 AI 工作负载性能。Geekbench AI 会测量设备的CPU、GPU 和 NPU 性能,以确定您的设备是否能够胜任当前和未来的前沿机器学习应用。
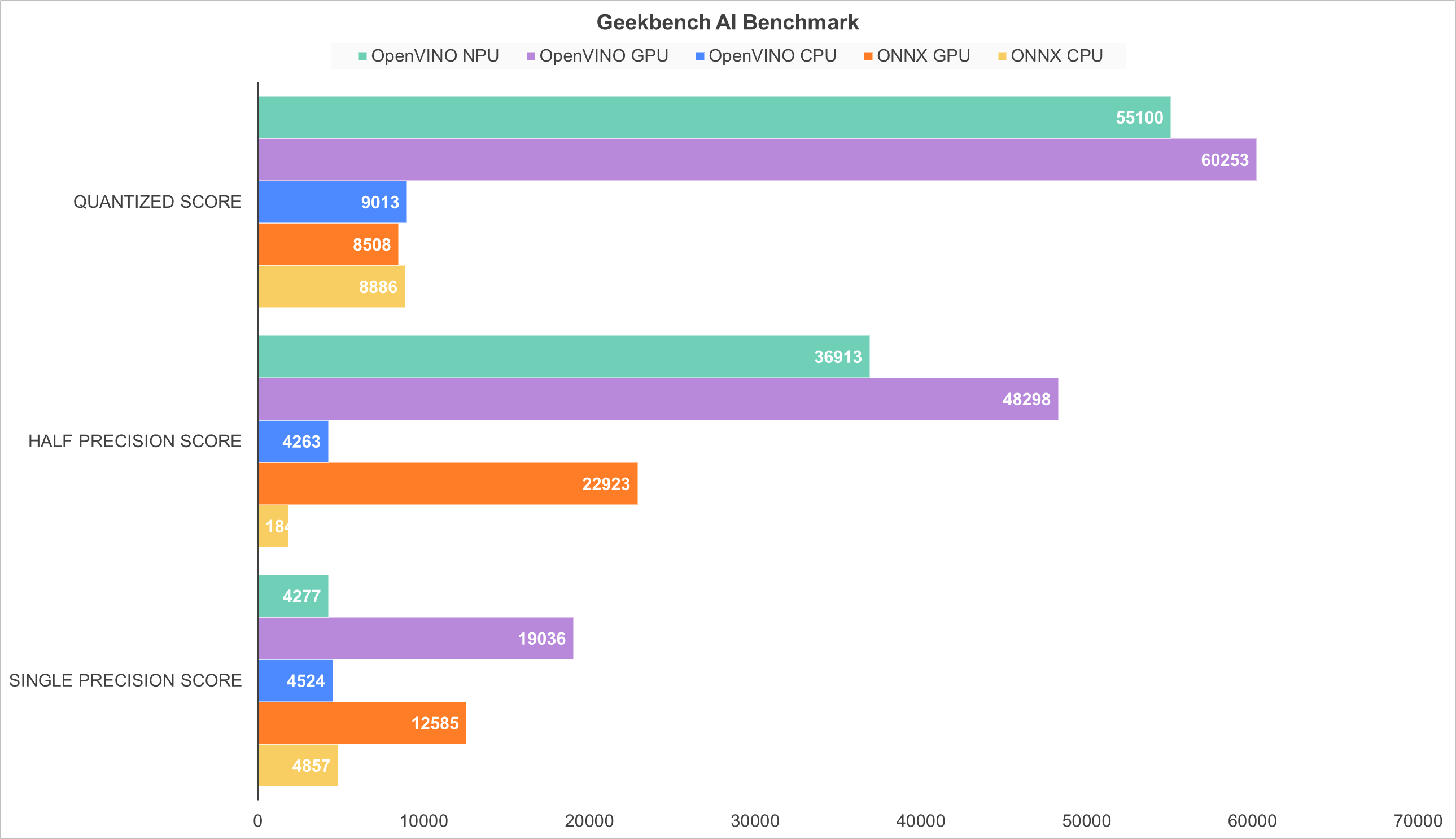
▲Intel OpenVINO 优化下的 Arc B390 核显,在量化、半精度、单精度三种主流 AI 精度中均表现出统治级性能。内置 NPU 紧随其后,在量化和半精度推理中同样展现了极强的专用加速能力。通用框架(ONNX)和纯 CPU 方案,与专用硬件的差距被进一步拉大。
-
在 Geekbench AI 的所有测试项中,Arc 核显都保持了最高得分,尤其是半精度(FP16)推理,性能是NPU的1.3倍、CPU的10倍以上,是本地AI推理的核心算力来源。
-
NPU 在主流推理场景中表现出色,量化和半精度(FP16)推理中,NPU 的性能是 CPU 的 5-8 倍,相比前代Meteor Lake / Arrow Lake,NPU AI性能有了大幅提升。完全可以独立承担轻量级AI 任务,同时功耗效率更高,适合低负载、长续航的场景。
-
通用框架(ONNX)的性能损失较大,无论是GPU 还是 CPU 方案,性能都被 OpenVINO 拉开了巨大差距,再次验证Intel原生优化对释放这颗处理器AI算力的决定性作用。
华硕NUC16 Pro搭载的Intel Core Ultra X7 358H的AI性能在2026年移动平台中属于顶级水平,特别是NPU主导的量化推理 和 iGPU 辅助的高吞吐量任务,非常出色。这使得它非常适合AI PC场景,能流畅运行本地生成式AI而无需依赖云端或独显。
OpenClaw
对于AI爱好者、职场办公人群而言,部署AI工具往往面临诸多困扰:环境配置繁琐、依赖包冲突、代码操作门槛高,无论是Openclaw(小龙虾)这类实用AI工具,还是各类大语言模型,都难以快速落地使用。而华硕NUC搭配华硕官方软件——华硕大厅可以彻底解决这一痛点,无需专业技术,一键就能完成部署,再加上NUC强悍的AI性能,让每一位用户都能轻松享受本地AI带来的高效体验。
▲下载并安装好华硕大厅程序,打开应用在左侧点击龙虾专区,我们这里使用EasyClaw安装。
▲EasyClaw基于OpenClaw框架打造的零配置桌面端AI智能体,一键安装,免除繁琐配置,集成了各家顶级模型。

▲安装完成后打开程序,可以在设置中切换语言至简体中文,默认是英文。

▲登录谷歌账号。
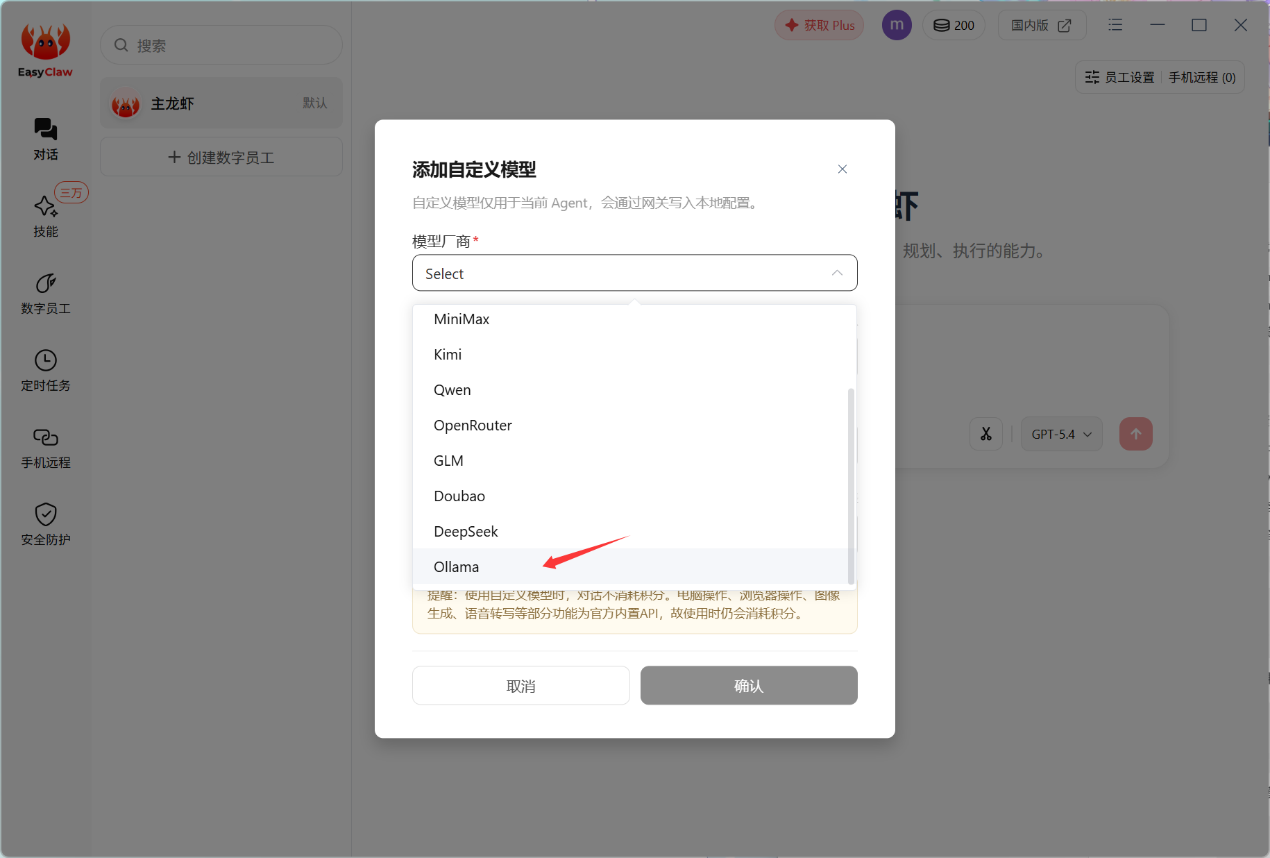
▲登录成功后,我们可以尝试部署一个本地的AI模型,直接在模型中选择自定义模型,选择Ollama。
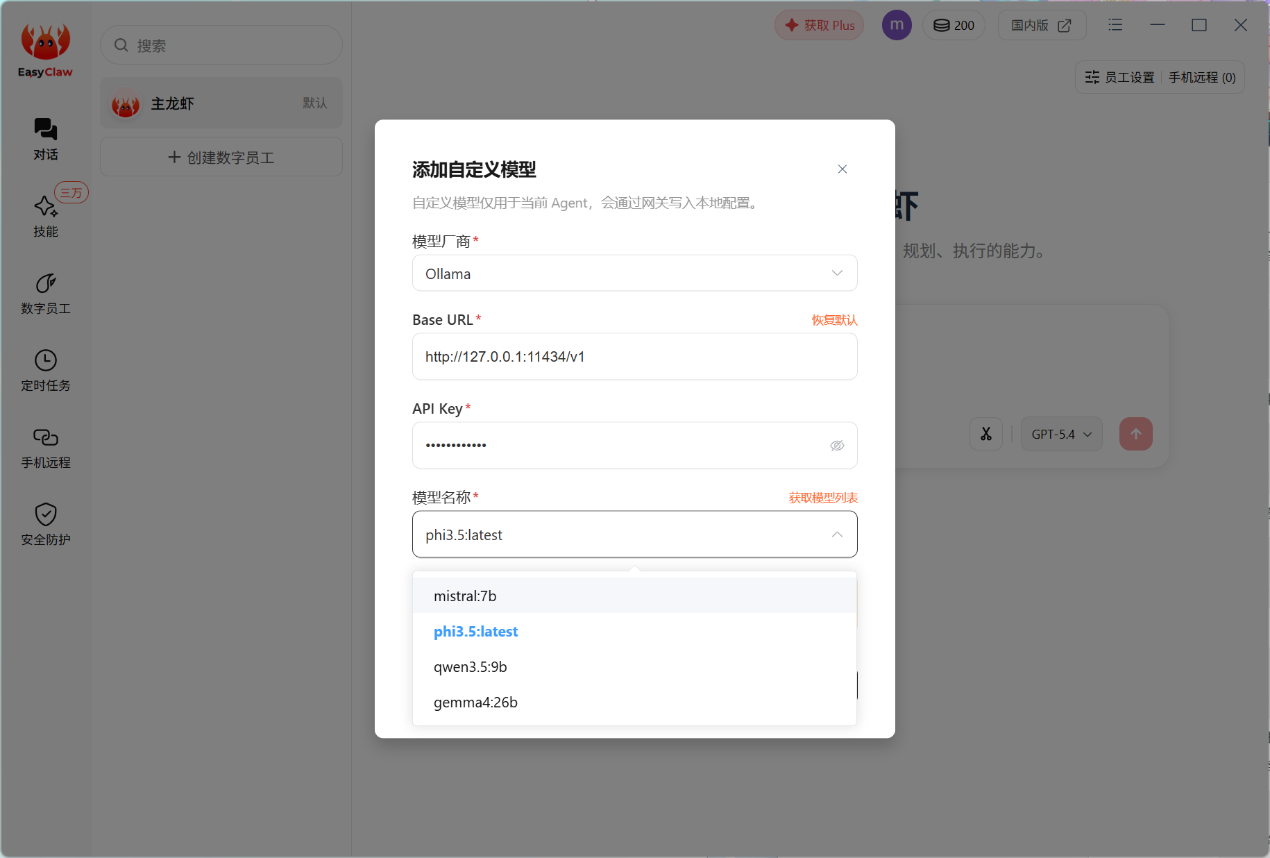
▲API Key填Ollama-local,其他默认。这里我已经在Ollama中安装了几个本地模型,使用qwen3.5:9b测试。
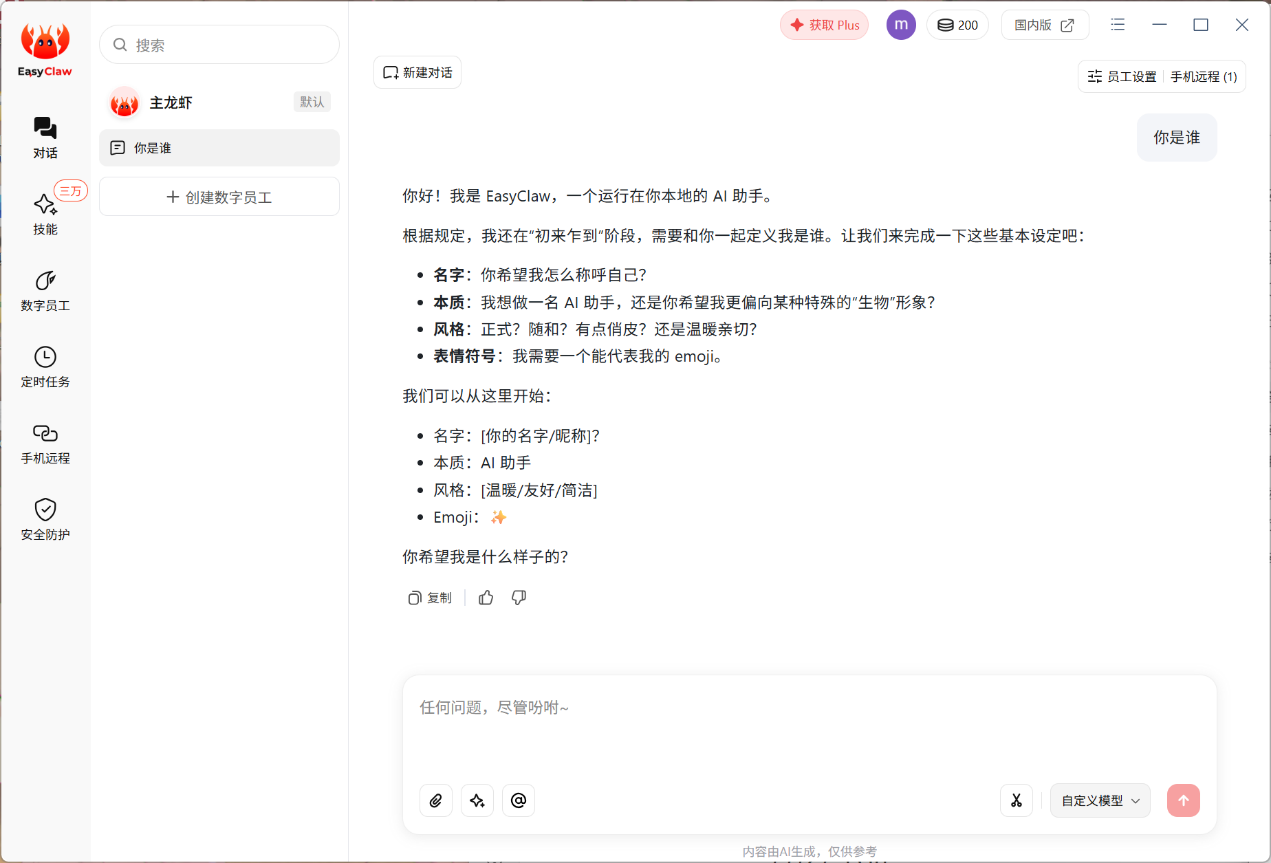
▲简单对话一下。如果使用Windows时就可以直接用EasyClaw程序进行本地对话。如果在户外的话,我们可以使用一个远程机器人。
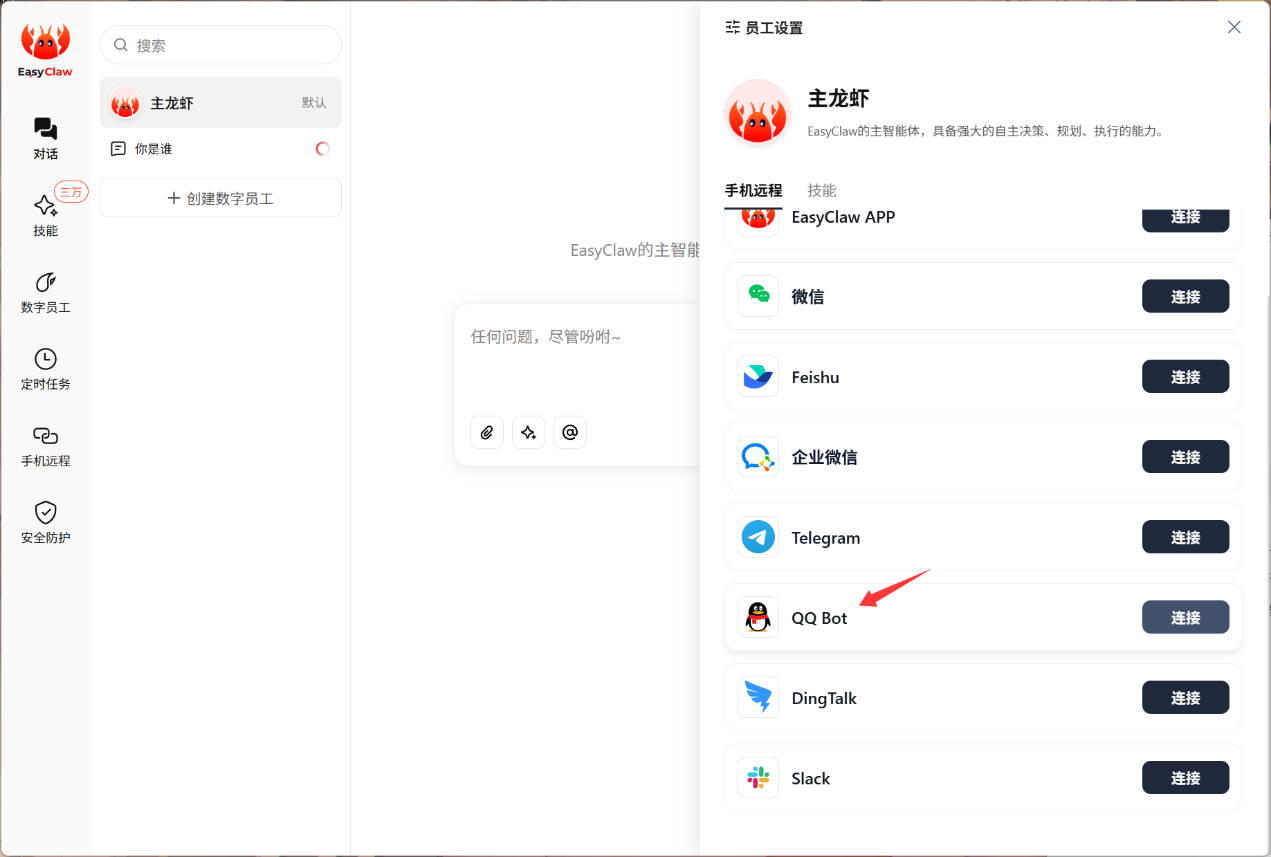
▲点击手机远程,选择QQ bot。
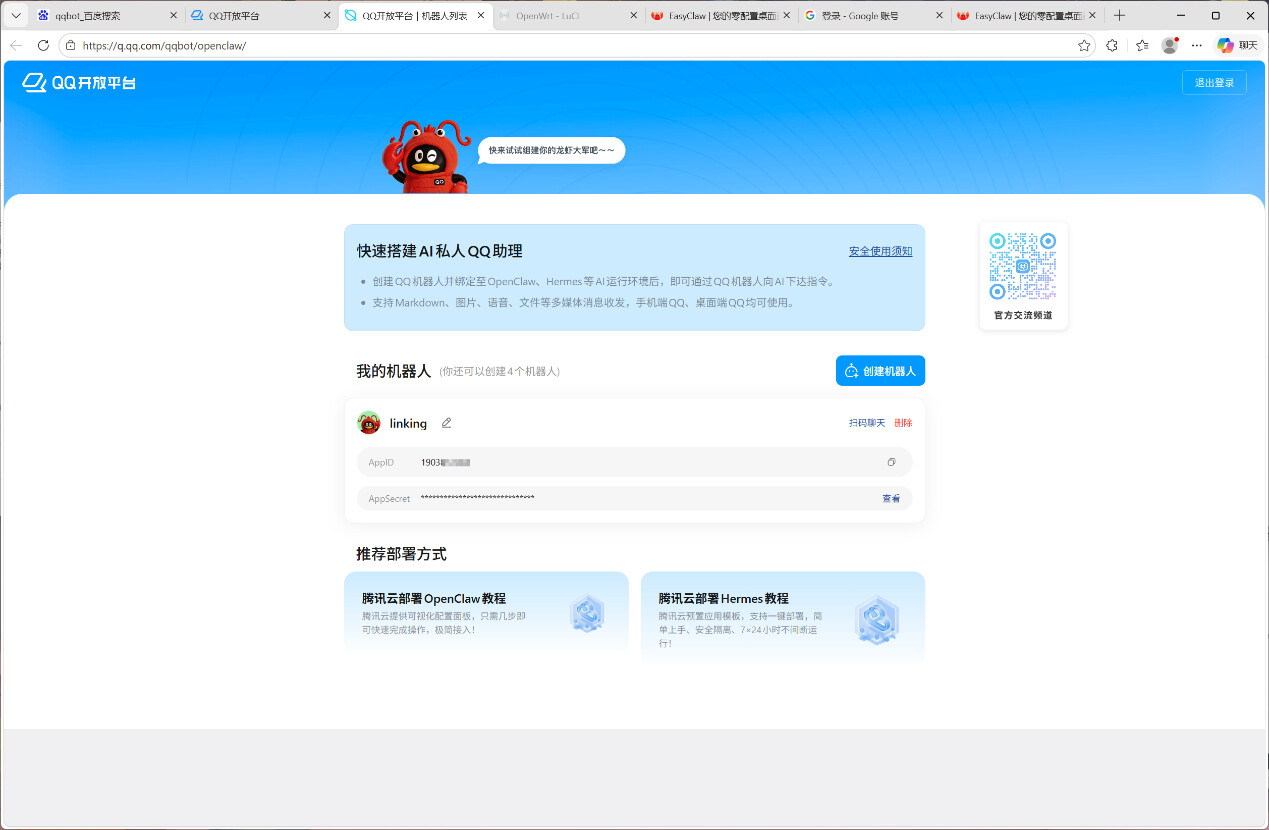
▲去QQ开发平台注册并创建机器人。
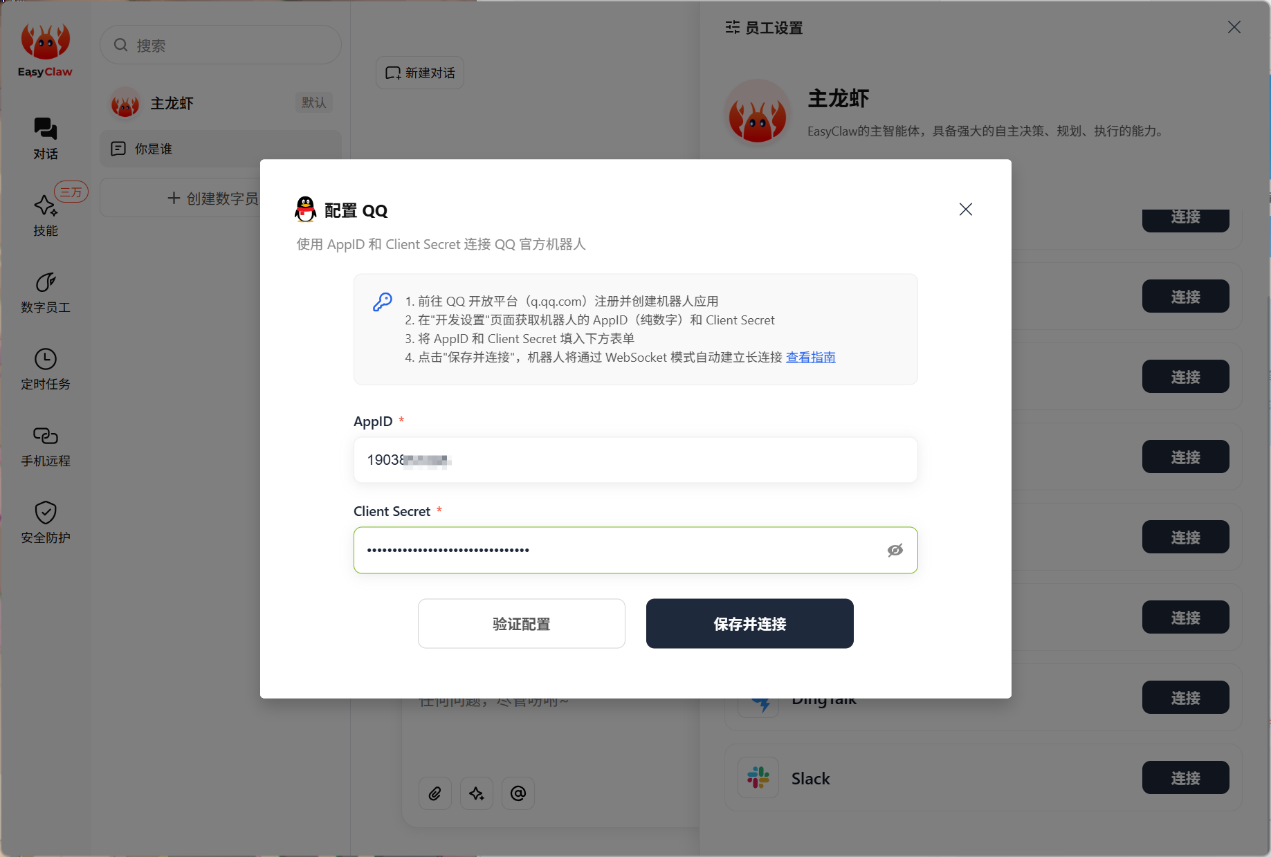
▲填好APP ID和APP Secret。
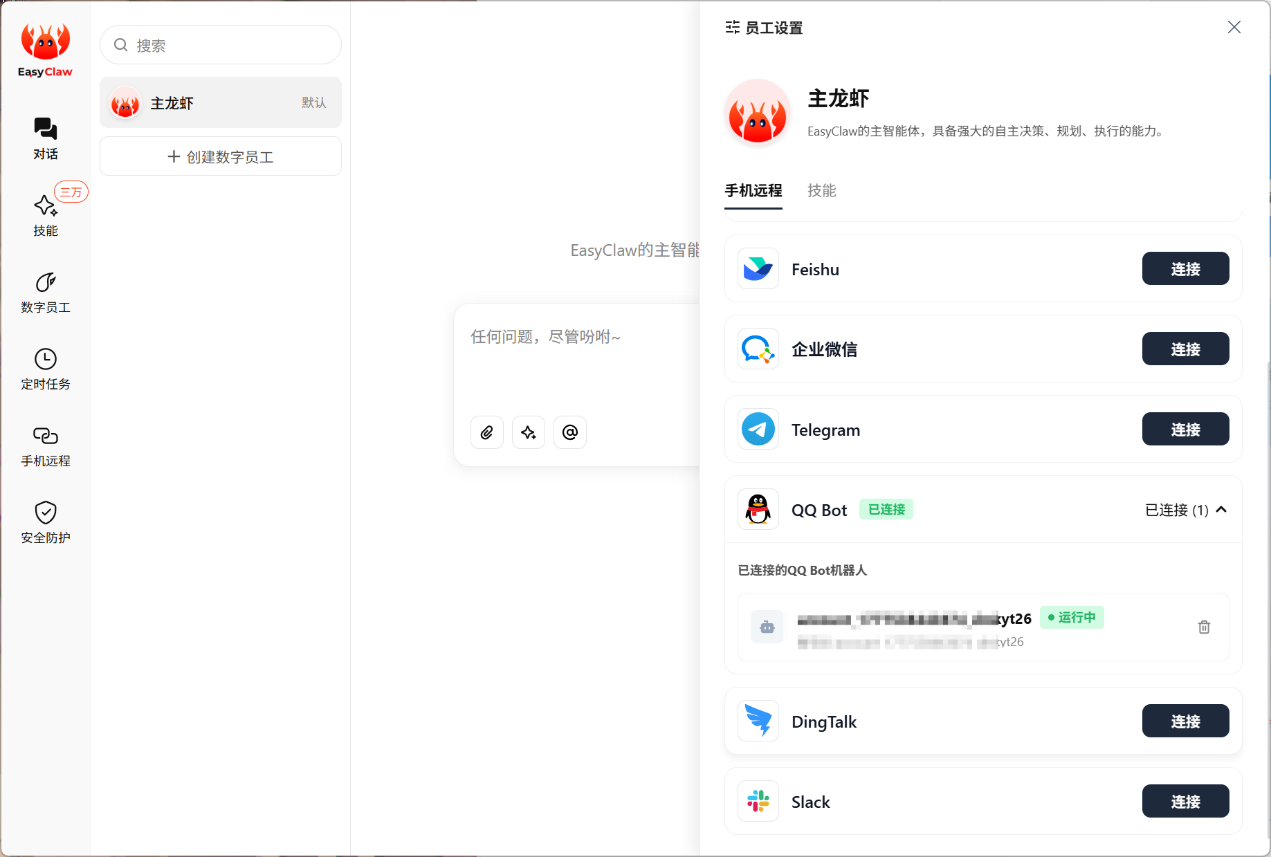
▲创建成功。

▲这样我们出门在外,随时掏出手机,用 QQ Bot 就能快速和AI Agent对话。例如获取景点推荐、路线规划和游玩攻略,不用再对着攻略 APP 翻来翻去,查信息、做规划都超省心,五一出行也能轻松又顺畅。
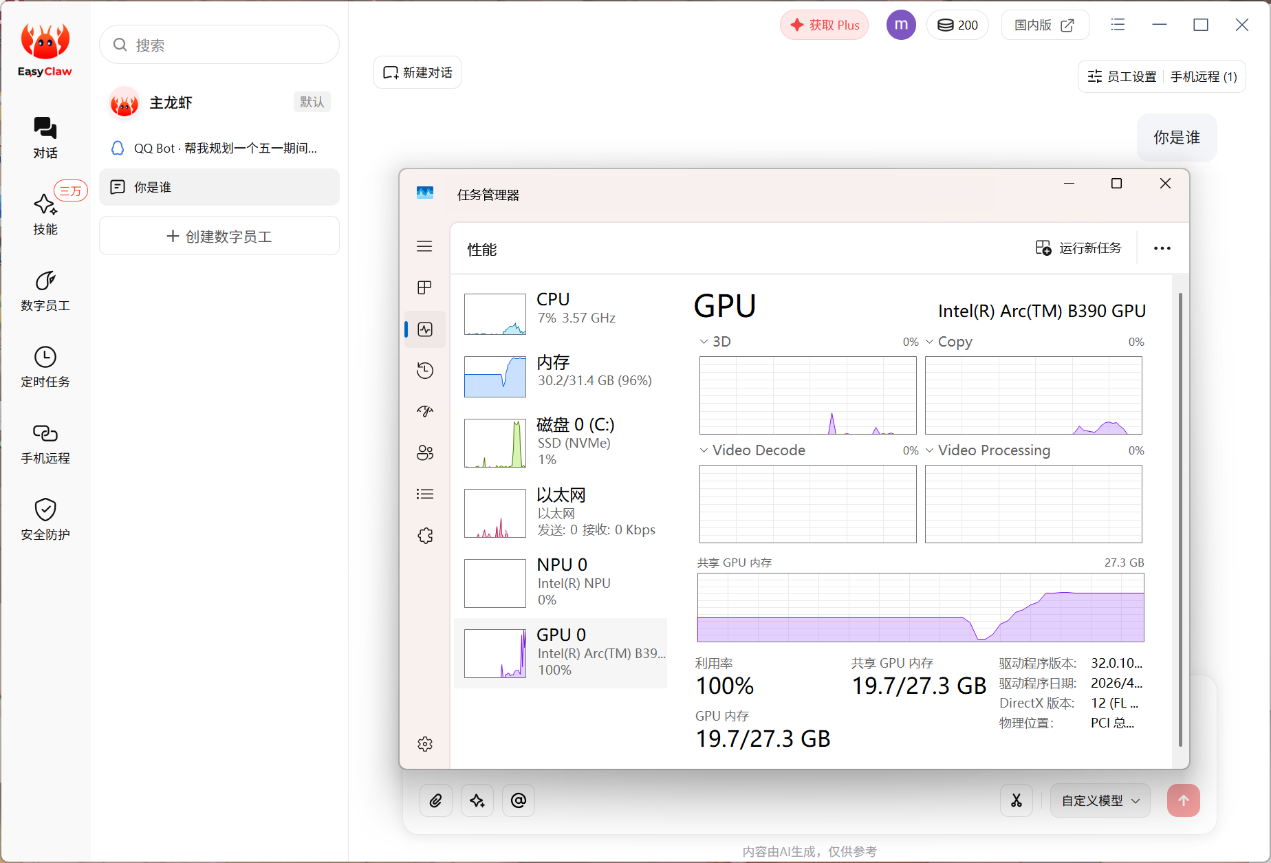
▲回到EasyClaw本地客户端可以看到,Intel Arc B390占用的内存也没到极限。
使用华硕 NUC16 Pro 本地部署 AI 模型,优势在于数据全程在设备内运行、隐私安全性高,无需联网即可使用,不受平台收费和限流限制,还能自由自定义模型参数与功能,使用响应稳定不拥堵;尤其适合处理包含商业机密、个人隐私的文档分析、代码调试、私密对话、本地数据批量处理等对数据安全要求极高的任务,也能在断网环境下稳定运行。缺点则是对硬件配置要求较高,运行时会占用大量硬件资源(GPU 显存),易造成电脑卡顿,且个人能运行的模型体量有限,在复杂逻辑推理、大规模多模态生成、前沿知识检索等场景下,综合能力比不上云端大模型,后续模型更新和维护也需要自己手动操作。
而云端大模型依托超大规模服务器集群,在模型参数规模、推理能力和功能丰富度上更具优势,同时无需担心本地硬件配置、环境搭建与模型维护的问题,对普通用户来说上手门槛更低,更适合创意写作、多模态生成、复杂逻辑推理、前沿信息查询等场景。
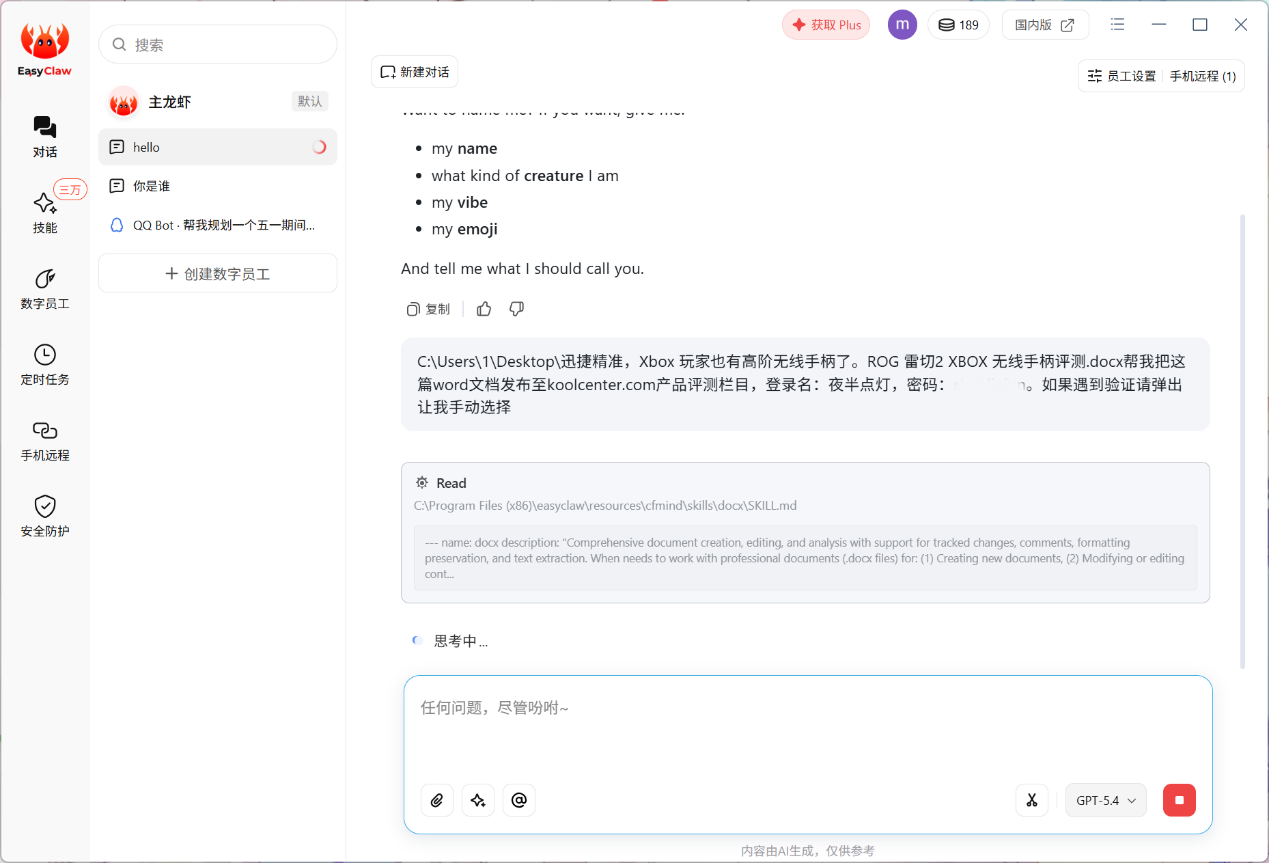
▲EasyClaw使用GPT-5.4云端大模型可以帮我们完成自动化的办公任务。例如可以让它帮我把写好的 Word 文档发布至 koolcenter.com 网站,全程无需手动操作。

▲遇到任何执行问题,EasyClaw搭载的GPT-5.4 云端大模型会自动纠错并调整执行策略,直到流程推进到登录并弹出验证码这一步。如果指令中没有明确要求手动验证,它甚至会自动下载验证码识别依赖库、自行匹配并完成验证,无需人工干预。
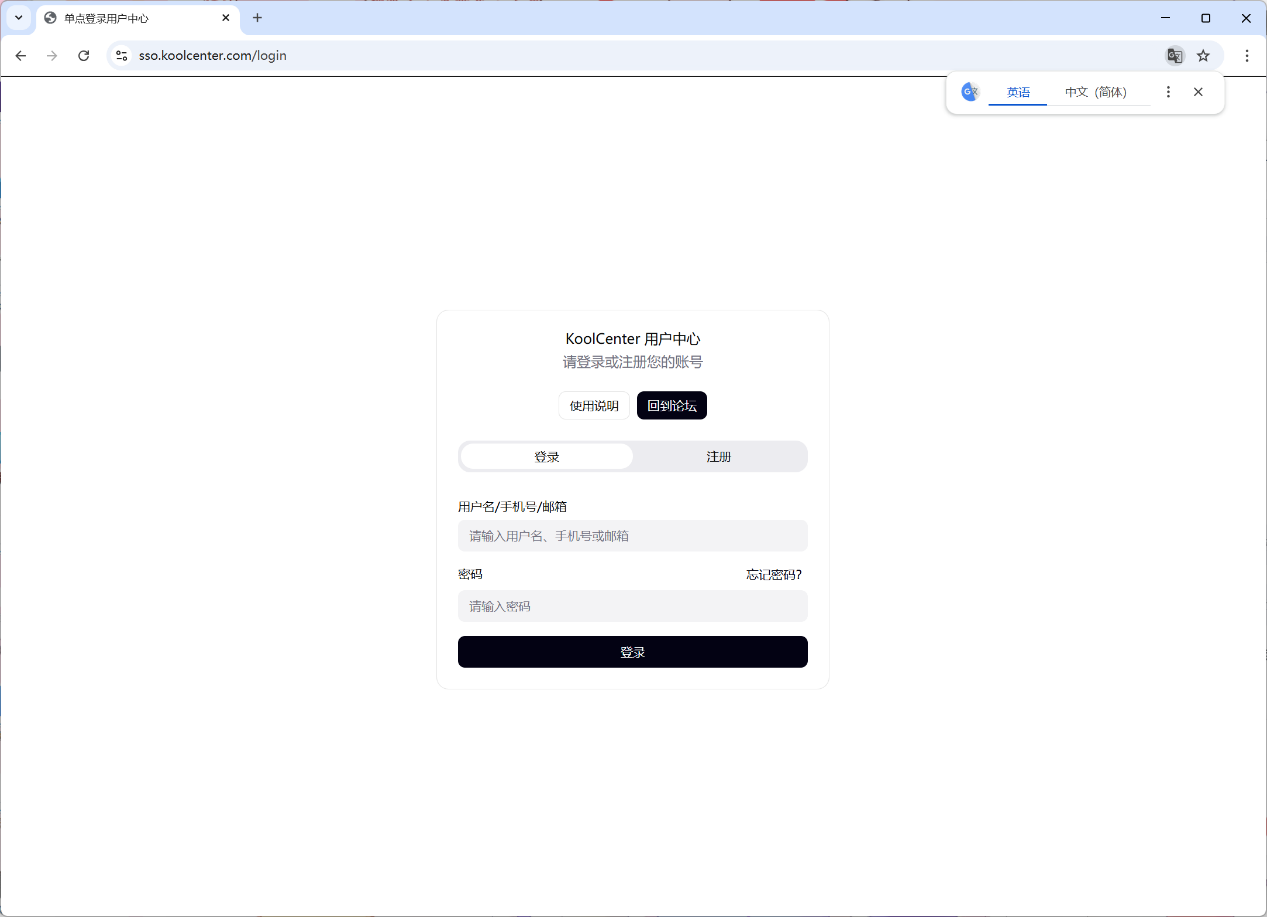
▲在 EasyClaw 拉起的 KoolCenter 用户中心登录界面中,手动填写账号密码、完成验证码验证后,后续的文档发布流程就会由 AI 全自动执行,无需再进行额外操作。
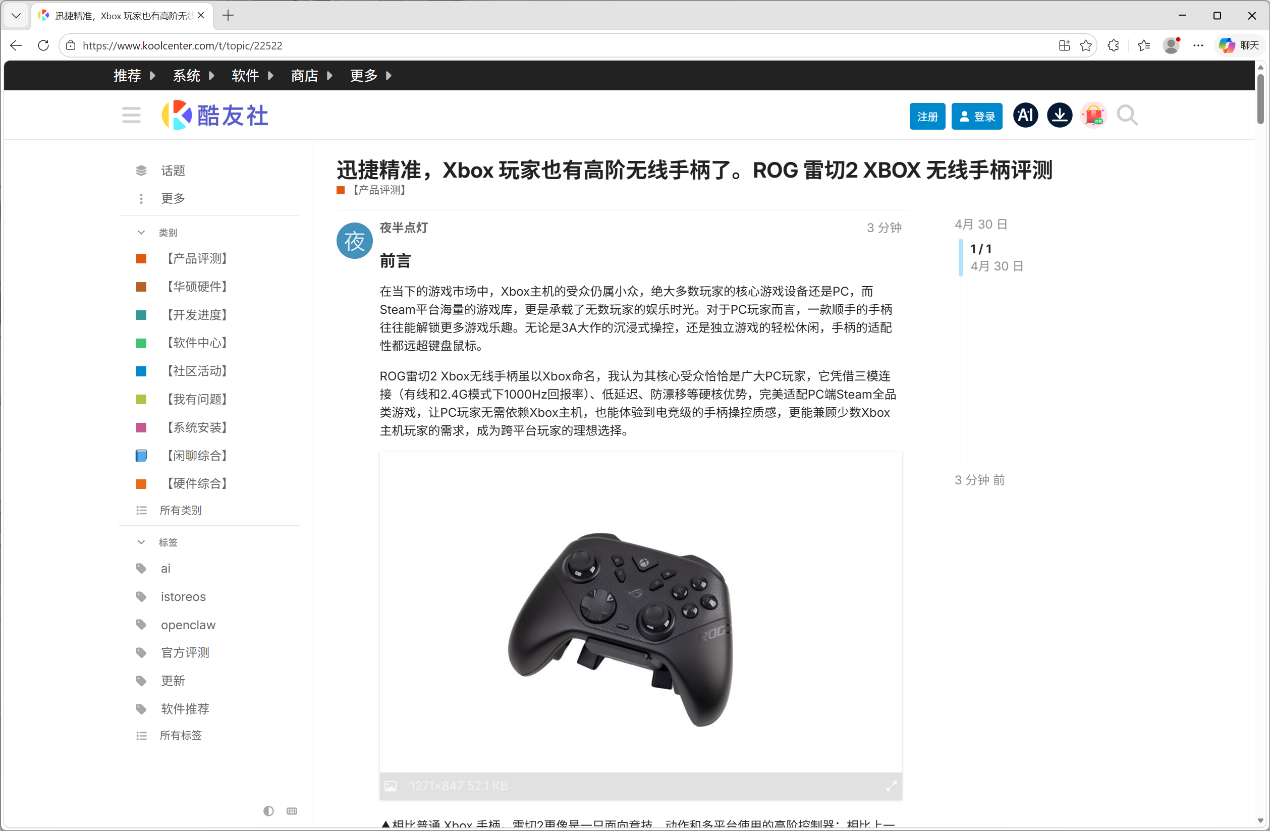
▲发布完成后,我们可以直接进入 koolcenter 网站查看最终效果。由于该网站后台没有提供直接导入 Word 文档的功能,人工发布时需要手动复制文字、上传并匹配图片,排版和对齐过程相当繁琐。而使用 EasyClaw 可以轻松完成这一系列复杂的文档解析、图文匹配与自动排版操作,无需手动干预,大幅提升效率。
EasyClaw 使用 GPT-5.4 云端大模型,除了可以帮我们完成自动发布文档这类任务,还能高效处理各类复杂的自动化事务,例如批量数据整理、网页操作、文件处理、定时任务执行等,大幅提升日常工作效率。唯一需要注意的是,使用云端模型需要消耗平台积分,账号每天会赠送 200 积分,如果需要处理大量复杂任务、超出每日赠送额度,就需要自行购买额外的积分来继续使用。
总结
AI 早已不是遥远的概念,而是未来工作与生活中不可缺少的一环,从日常办公自动化、内容创作,到数据处理、智能交互,AI 正在重塑每一个场景的效率边界。想要及时拥抱这场变革,一台足够强大、易用的智能终端,就是我们接入未来的关键入口。而华硕NUC16 Pro,正是这样一款为 AI 时代量身打造的迷你主机。
它搭载的 Intel Panther Lake 架构 Intel Core Ultra X7 358H 处理器,搭配 Arc B390 核显与 NPU 5 加速引擎,带来高达180 TOPS的平台总AI算力,既能流畅运行7B–13B级本地大模型,实现隐私安全的离线 AI 办公、代码生成与知识问答,也能通过 OpenVINO 框架充分释放硬件潜力,让本地推理速度媲美专业设备;更能无缝衔接云端大模型,配合 EasyClaw 智能体完成文档自动发布、网页自动化、批量数据处理等复杂任务,兼顾本地算力的安全可控与云端模型的高效便捷。
更重要的是,华硕 NUC16 Pro 以极简的部署体验打破了AI应用的门槛。通过华硕大厅即可一键部署本地AI模型,无需复杂配置;搭配QQ Bot远程控制,更能随时随地调用AI能力处理任务,让普通人也能轻松拥抱AI带来的效率革命。在这个AI加速迭代的时代,拥有华硕 NUC16 Pro,就等于握住了一张通往未来的 “入场券”。它不仅是一台迷你主机,更是你提前布局AI生产力、紧跟时代浪潮的底气,让我们无需等待,就能以强大的本地算力与灵活的云端能力,从容迎接AI驱动的未来。